반응형
INTRODUCTION
- Infrared image와 visible image fusion에 있어서 기존의 CNN-based fusion methods는 last layer results에 대해서만 image features를 사용하기 때문에 middle layers에서 얻는 유용한 정보들을 잃어버리는 문제가 존재
- 이를 해결하기 위해 본 연구에서는 encoding network와 decoding network로 구성되는 novel deep learning architecture을 제시
- Encoding network는 convolutional layer와 dense block으로 구성되고 feature maps을 만드는데 활용
- Decoding network는 fusion된 feature maps을 reconstruct 하는데 활용
PROPOSED FUSION METHOD
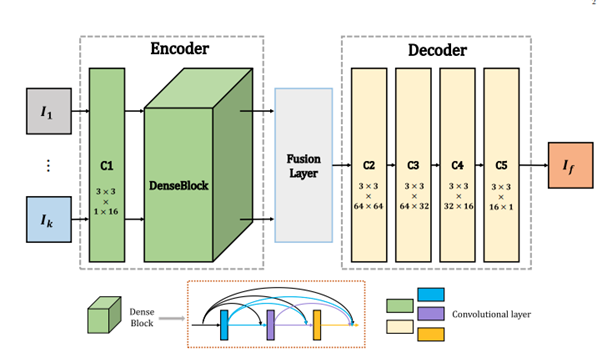

Input infrared and visible images(gray scale images)는 I1,..., Ik (k>=2)로 정의
- 본 연구의 architecture는 세가지 파트로 나뉨: encoder, fusion layerm decoder
- Encoder는 두가지 파트를 가짐 (C1과 DenseBlock) 그리고 DenseBlock 의경우 3개의 convolutional layers로 구성됨
- DenseBlock의 각 layer의 output은 다른 layer의 input으로 들어가는 cascade 형태
- 본 연구의 architecture의 convolutional layers의 필터 크기는 모두 3 X 3이고 stride는 1, pad는 reflection mode를 사용하고 Activation function은 ReLu를 사용
- 본 논문에서 Fusion Layer에서는 후술 할 두 가지 방법 중 하나를 선택해서 사용
- Decoder는 네가지 convolutional layers를 포함하고 fusion layer의 output이 input으로 들어감
TRAINING

- Training phase에서는 fusion layer는 무시하고 encoder와 decoder networks만 고려
- Encoder와 decoder weights가 fix 되면 적절한 fusion strategy를 선택
- 이러한 training strategy는 fusion layer에 다양한 fusion strategy를 넣을 수 있고 특정한 상황에 적절한 fusion strategy를 선택하는 이점을 가짐
- Input image를 더 정확하게 하기 위해 loss function L을 minimize
- Loss function L은 pixel loss와 structural similarity (SSIM) loss로 구성
- Pixel loss Lp는 다음과 같은 식에 의해 계산 (output O와 input I의 Euclidean distance)
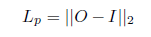
O와 I는 각각 ouput과 input images를 의미 - SSIM loss Lssim은 다음과 같은 식에 의해 계산

- SSIM은 두 이미지 간의 structural similarity를 나타냄. 0~1 값을 가지며 1에 가까울수록 원본 이미지와 유사

- SSIM loss 와 pixel loss 간에는 3000배의 크기 차이가 존재하기 때문에 SSIM loss에 λ를 1, 10, 100, 1000을 설정해주며 training
- Training phase에서는 infrared images와 visible images이 부족하기 때문에 visible images인 MS-COCO data set을 gray scale로 변환 후 256X256 resizing 하여 training
- Learning rate 1X10^(-4), Batch size 2, epochs 4 로 설정
FUSION LAYER(STRATEGY)
1) Addition Strategy
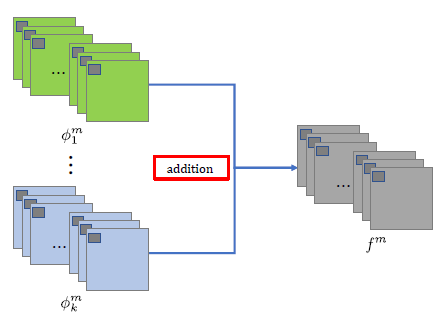
- Encoder로 부터 나온 각각의 feature map들을 단순히 더하여 합성 feature map 생성
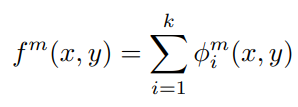
Addition Strategy 식. φ는 Encoder로 부터 얻은 feature map을 의미하고 f는 합성된 feacure map을 의미한다.
2) L1-norm Strategy
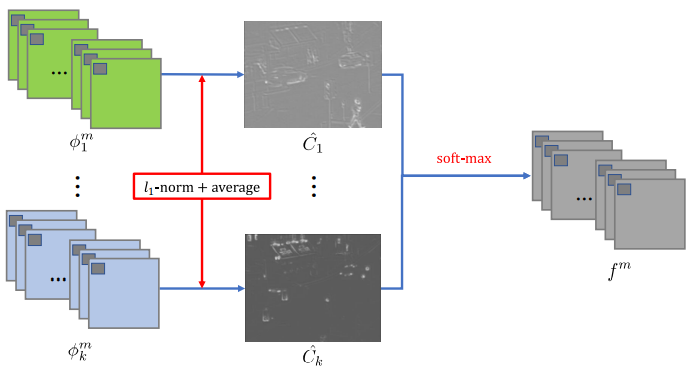
- Encoder에서 나온 feature map들이 한 장의 이미지로 다 합쳐 C 이미지 획득
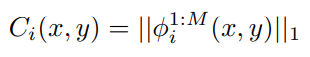
- 획득한 C 이미지에 Average filter 적용하여 Cˆ 획득
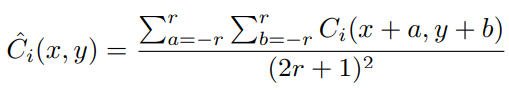
- 합성된 feature map f는 다음과 같은 식에 의해 생성
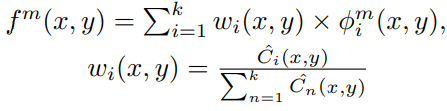
ANALYSIS
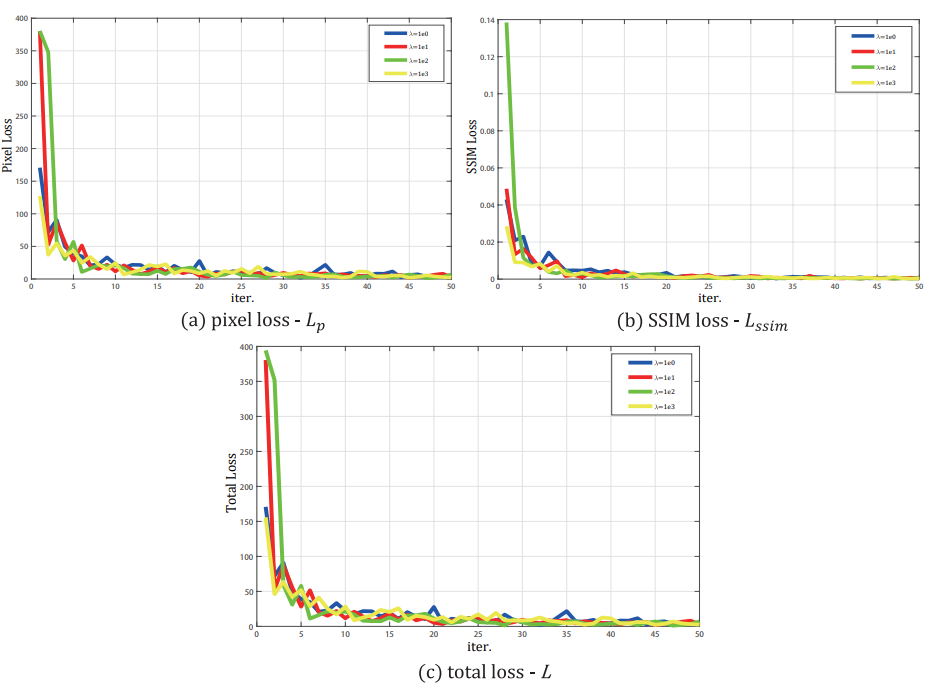

- λ = 1000 일때 Loss의 수렴하는 정도가 제일 빨랐다.
- 하지만 40000회 이상 반복했을 때 λ의 값과 상관없이 모두 최적의 weight값을 얻을 수 있었다.
CONCLUSION
- CNN 베이스의 Dense block 이라는 cascade 구조의 적외선 및 가시광선 이미지 합성 딥러닝 모델을 제시하면서 기존의 합성 모델들보다 더 세밀한 특징을 추출하여 합성
- gray scale image뿐만 아니라 RGB scale image도 아래 그림과 같이 채널을 분리하여 합성 가능
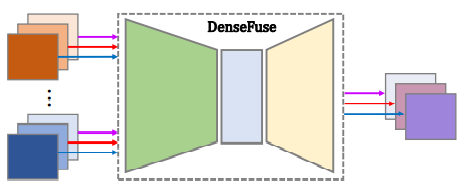
RGB image 합성 framework - DenseFuse 모델은 Encoder, Fusion layer, Decoder로 구성되어있고, Encoder의 입력으로 infrared 와 visible image가 들어가면 CNN layer와 Dense block을 통해 feature map들을 각각 획득한다. 획득한 각 입력에 대한 feature map들은 Fusion layer에서 특정 fusion strategy (본 논문에서는 Addition strategy와 L1-norm strategy가 소개되었다.)에 의해 하나의 feature map으로 합쳐진다. 합쳐진 feature map은 decoder의 입력으로 들어가고 decoder에서 한 장의 이미지를 출력으로 생성
반응형